The method: no favored hypothesis
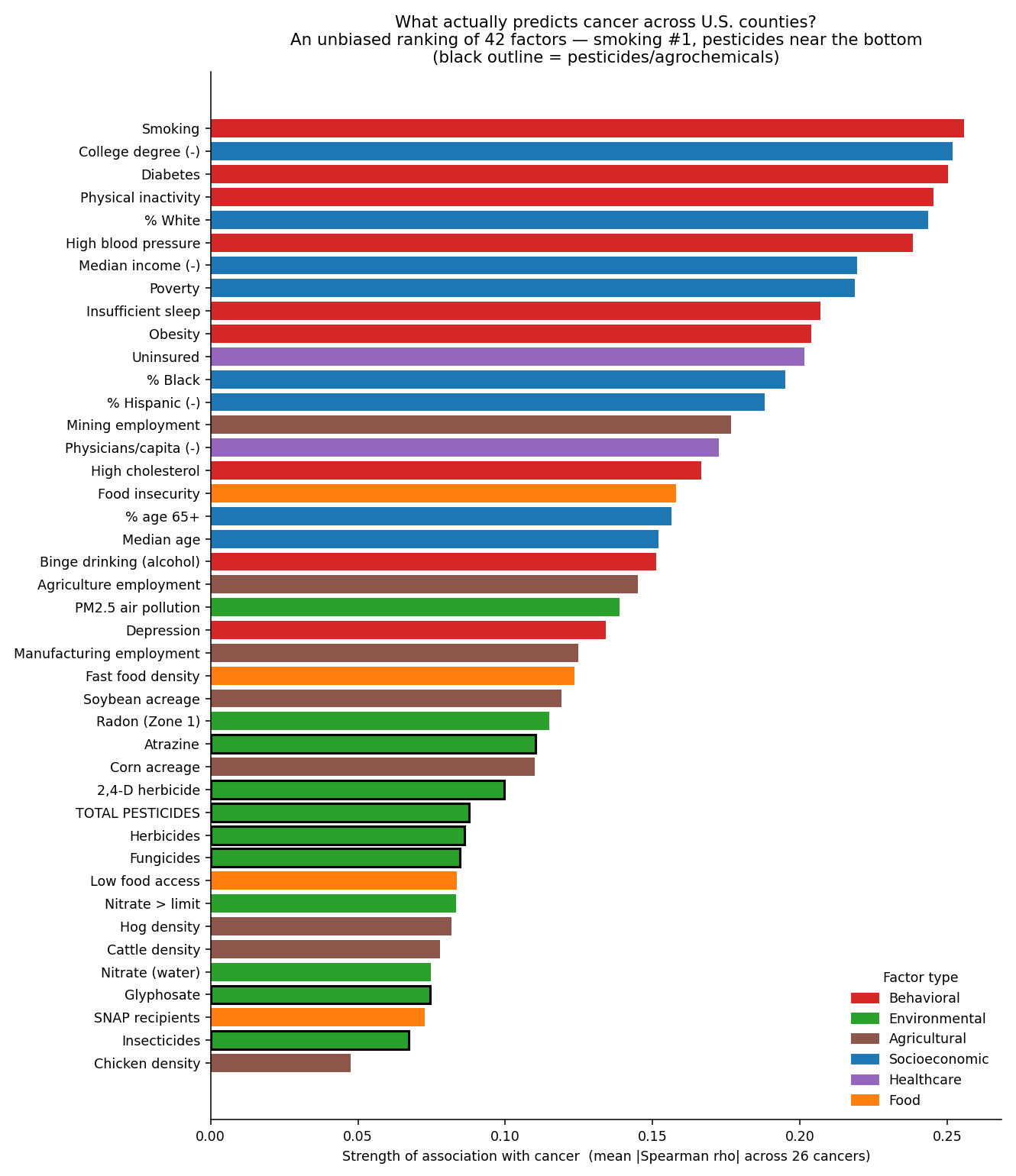
Three deliberately agnostic views, none privileging any exposure: (1) rank correlations of every factor against every cancer, with Benjamini–Hochberg false-discovery control across the full grid; (2) random-forest permutation importance per cancer; (3) LASSO sparse selection. If the pipeline is honest, the known carcinogens should rise to the top on their own. Smoking leads, but in a tight top cluster with socioeconomic and metabolic factors (first in ~56% of bootstrap resamples); the bootstrap-robust conclusion is that pesticides stay in the bottom third no matter how the data are resampled.
The ranking
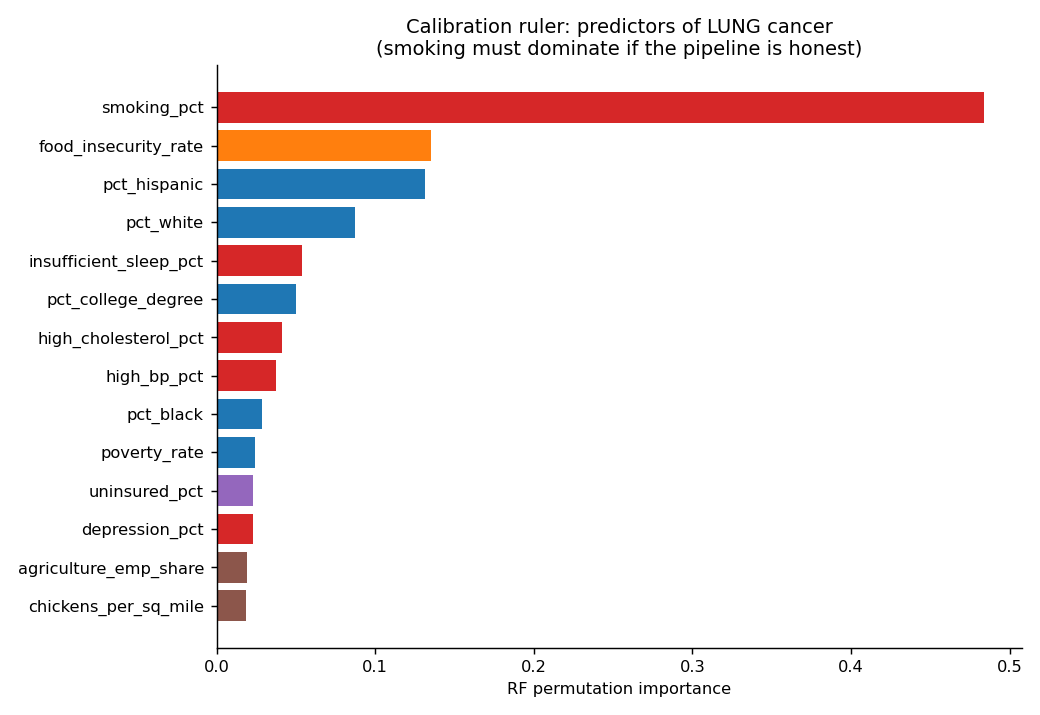
The pipeline is provably honest
For lung cancer specifically, smoking's importance is 3.6× the next factor — exactly what a valid method must show. This is the calibration that licenses trusting the rest of the ranking.
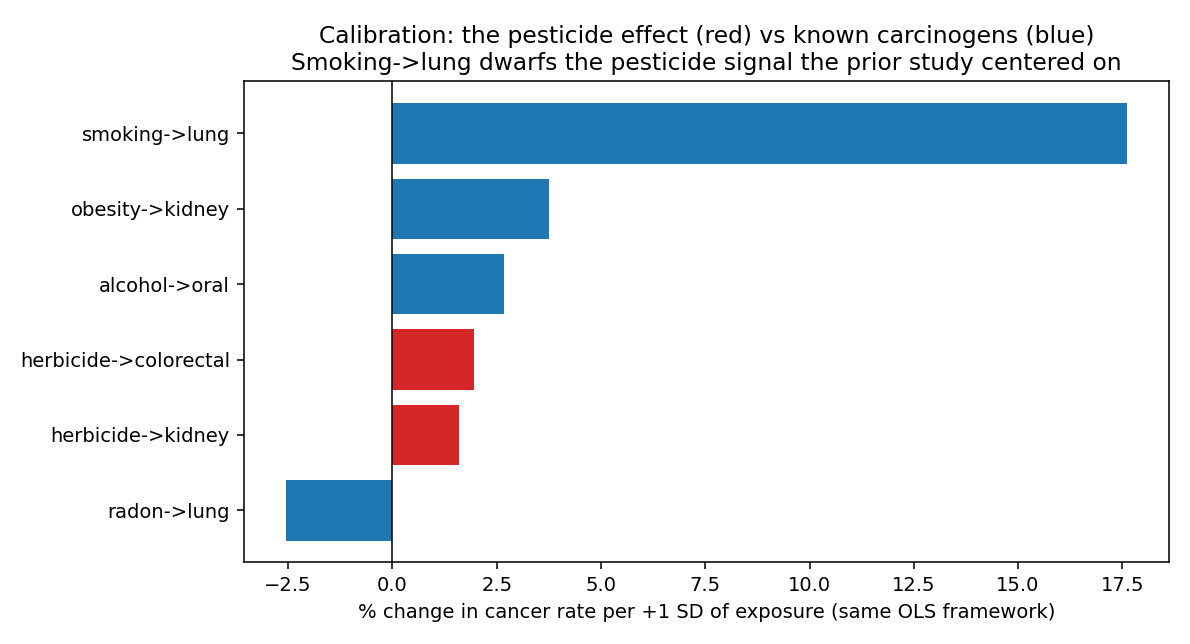
The pesticide signal, audited honestly
The original study's pesticide–kidney/colorectal associations do reproduce — but they are tiny (+1.6% and +2.0% per SD) and dwarfed by known carcinogens in the same regression.
A tell-tale sign of confounding
When pesticides are scanned against all 26 cancers (adjusting for 8 confounders), the strongest association is melanoma — biologically implausible as a pesticide effect, and a clear signature of rural/outdoor/agricultural confounding (pesticide density tracks agricultural, sun-exposed, higher-%white land). Liver is negative; kidney — the original headline — is marginal at best. The original study selected the two narratable hits out of a confounded agricultural gradient. (Independent check: the exact ranking is method-dependent — under rank-based correlation liver leads and kidney barely survives FDR — but melanoma sits at the top either way.)
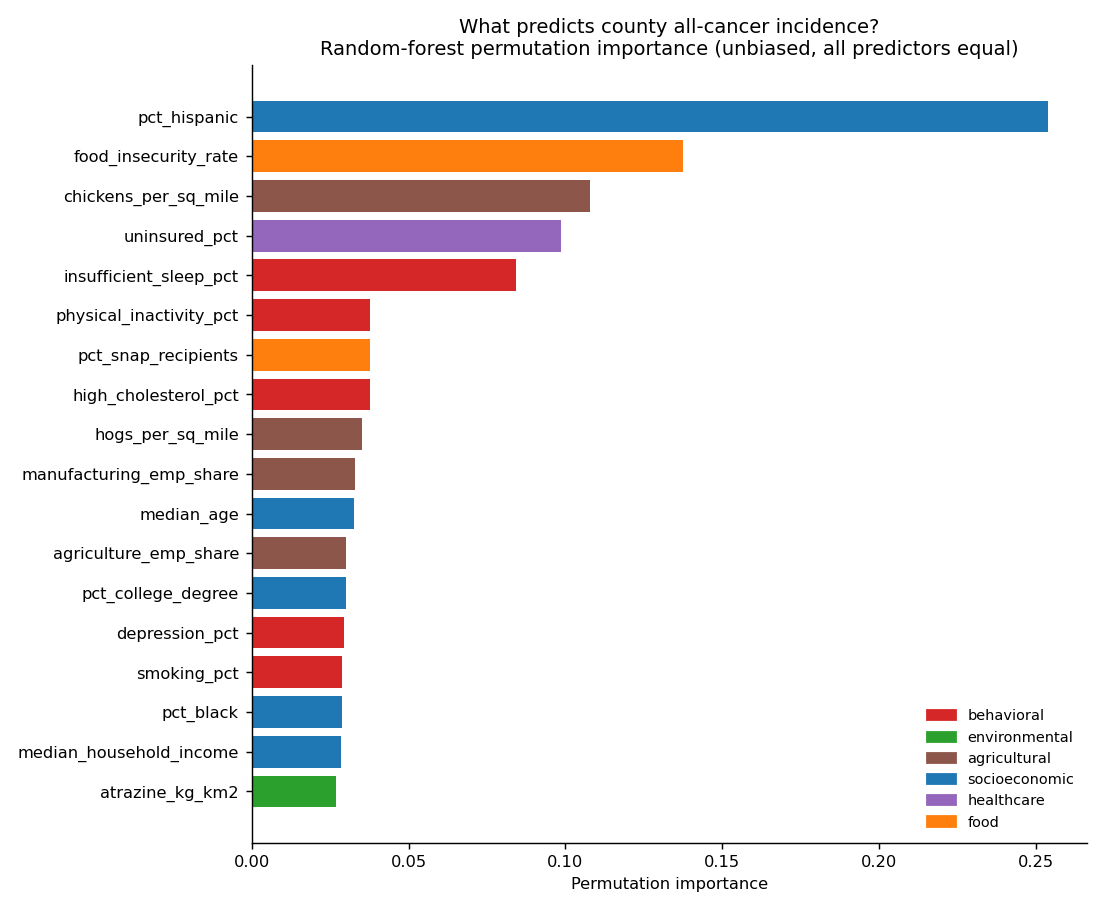
Why “all-cancer combined” looks different
For total cancer burden, population composition matters most — demographics and socioeconomic structure outrank any single exposure, and the only agrochemical to appear (atrazine) sits near the bottom. Specific carcinogens show up in specific cancers (smoking→lung), which is why the per-cancer ruler is the honest test.
Read this as ecology, not destiny
These are county-level correlates, not individual causation. Ecological associations are confounded by everything that varies geographically; the radon sign-flip is a live example. The value here is honest ranking and magnitude calibration — which is enough to show that the original study's emphasis was misplaced.
Reproduced by analysis/p2_exposome_scan.py and p1_audit.py against master_county_data_v4.csv (+radon).